Update: Now in French too
Update 2: and in German
Update 3: now with Web Speech API (scroll to the bottom)
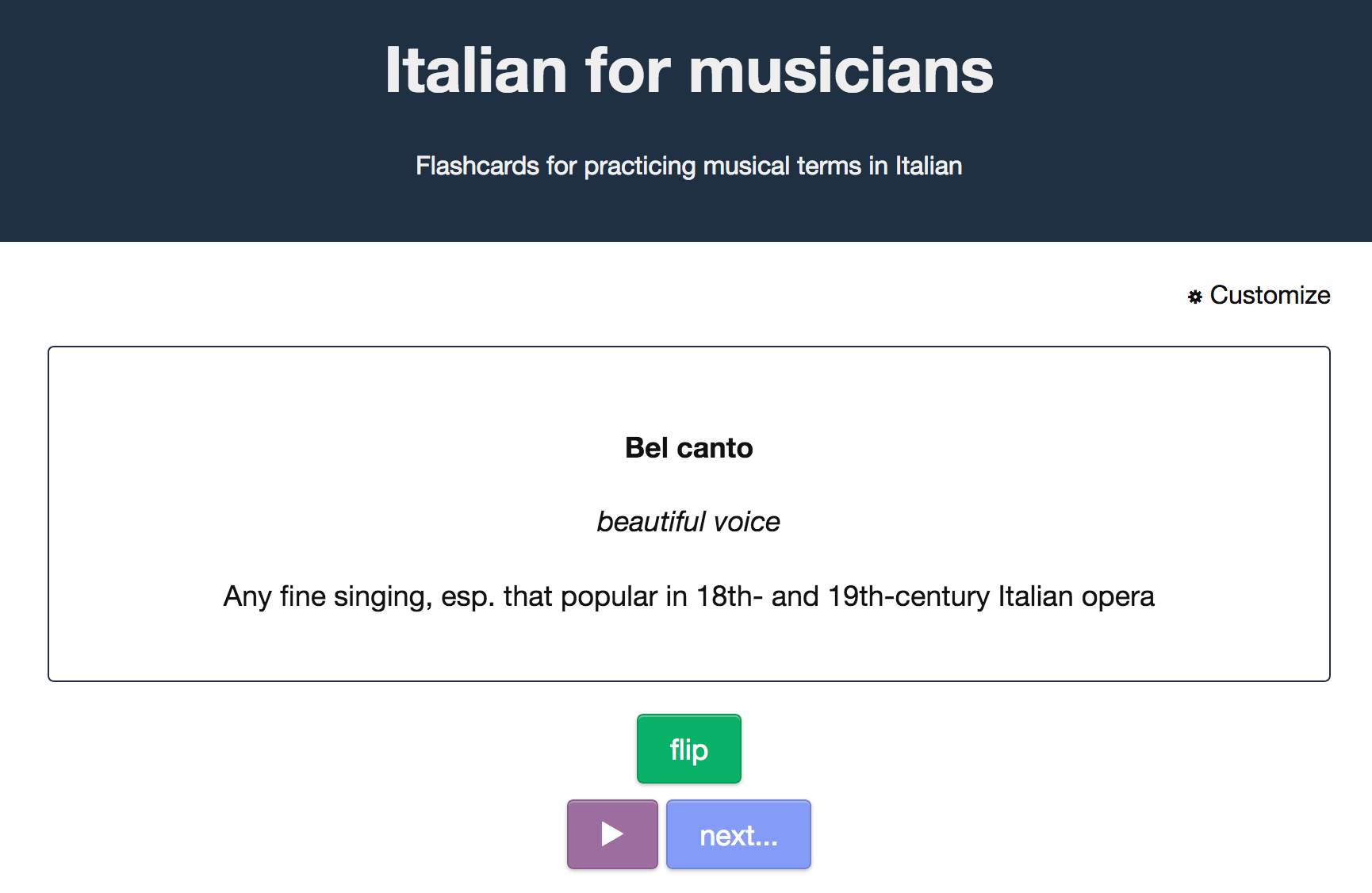
Here's a little app that gives you flashcards of Italian words used in music:
https://www.onlinemusictools.com/italiano/
It also pronounces the words in four different voices.
The code for the tool:
https://github.com/stoyan/italiano
A few implementation notes after the break (screenshot).
React CRA-ft
The tool is a little React app. Its bones are generated by create-react-app. It also uses a wee additional tool I call CRAFT (Create React App From Template). More about these here.
Wikipedia Table-to-JSON
The Italian words I found on Wikipedia, neatly divided into sections and tables. Just as I opened the browser console to start hacking on a script to scrape these tables, I remembered I already have a tool for that!
The process wasn't completely lacking manual intervention, but relatively painlessly I got a nice chunk of JSON files, one for each category of words, check'em out.
Speak
The cute part about this tool is the pronunciation of the words. For this, I reached to the help of MacOS's say command-line tool. This tool comes free with the OS and you can tweak the voices in your Accessibility preferences (short post about all that here).
I thought I'd write a script to loop thought the JSON files and then say each word of each file with each of the 4 Italian voices that are available.
You can see the whole script but here's just the main loop:
readDir(dataDir).forEach(f => {
if (f.startsWith('.')) {
return; // no .DS_Store etc, thank you
}
const file = path.resolve(dataDir, f);
const jsonData = require(file);
[
"Alice",
"Federica",
"Luca",
"Paola",
].forEach(voice => {
jsonData.forEach(definition => {
const word = definition[0];
const outfile = `voices/${voice}/${justLetters(word)}`; // .aiff is assumed
console.log(outfile);
spawn('say', ['-v', voice, '-o', outfile, word]);
});
});
});
So if you have the word "Soprano" the script runs:
say -v Alice -o voices/Alice/soprano Soprano
... then Federica instead of Alice and so on, for each of the 4 voices. And you end up with voices/Alice/soprano.aiff audio file.
Once all is done, you go in each voice's dir and convert all AIFF files to smaller, compressed MP3 using ffmpeg:
for f in *.aiff; do ffmpeg -i $f "${f%.*}.mp3"; done
And delete the sources:
rm -rf *.aiff
Reuse the language data
Please. My tool/UI is out there for you to practice, but I know there are tons of flashcard-style and language-learning apps out there. If you want to take the structured data I hereby slaved over and import it to your favorite app, the JSON and MP3 files are self-contained in this directory:
tree/master/public/italiano.
Let me know if you do something with this.
say -v Stoyan Ciao cari!
Thanks for reading! Enjoy the flashcards and say and all that.
Update: Web Speech API
Thanks to Marcel Duran's tweet I figured I was living under a rock and missed out on all the fun that is the Web Speech API.
So for browsers that support that API which is a lot of browsers, people don't need to download MP3 and the whole say jazz is unnecessary. These words can be generated in the browser. Yeweeyeye! Yaw! Yeet!
First bump though - browsers. See what happens when you try to check what voices are available:


Huh? You call the same thing and get different results. Not cool. Turns out in FF and Chrome this API is asynchronous. And the right way is to subscribe to an event:
speechSynthesis.onvoiceschanged = () => {
voices = speechSynthesis.getVoices().filter(v => v.lang === 'it-IT');
}
Cool. Turns out in Safari there's no onvoiceschanged. But getVoices() appeared synchronous in my testing.
So with all the browser sniffing, here's what I ended up with in order to get a list of Italian-speaking voices:
let webvoices = null;
if (
'SpeechSynthesisUtterance' in window &&
'speechSynthesis' in window
) {
if ('onvoiceschanged' in speechSynthesis) {
speechSynthesis.onvoiceschanged = () => {
webvoices = getVoices();
}
} else if (speechSynthesis.getVoices) {
webvoices = getVoices();
}
}
function getVoices() {
return speechSynthesis.getVoices().filter(v => v.lang === 'it-IT' && v.localService);
}
(The localService bit is so that there's no download, because Chrome offers more voices but they require internet connection)
Now webvoices is my array of Italian speakers and I randomly pick one every time you hit Say.
If webvoices is still null, I fall back to what I had before.
if (webvoices) {
const u = new SpeechSynthesisUtterance(term[0]);
u.voice = webvoices[Math.floor(Math.random() * webvoices.length)];
speechSynthesis.speak(u);
} else {
this.state.audio[Math.floor(Math.random() * this.state.audio.length)].play();
}
Awesome! Here's the diff and the Safari follow-up.
Update: moved back to the MP3 while keeping the web speech for offline use. I just didn't like how it sounds in French, especially words like "prelude" (sounds like prelune) and "rapide" (again sounds like rapine)




